
By Jasper Callaert – Data Engineer
Hi, my name is jasper callaerts and you might already know me from my previous blogs about aws glue. In this blog, I will talk about machine learning & analytics. These are powerful tools for understanding and improving business processes, but they can be complex and time-consuming to set up and manage. This is where aws sagemaker comes in. This blog will tell you about this service, explore the different features of sagemaker together with its pros and cons and will give you a step-by-step approach for building your own machine learning algorithm on aws.
What is AWS SageMaker
AWS SageMaker is a fully-managed service on the Amazon Web Services (AWS) cloud platform that enables developers and data scientists to build, train, and deploy machine learning models at scale.
AWS SageMaker is a platform for machine learning and analytics that makes it easy for developers and data scientists to build, train, and deploy machine learning models. It provides a variety of pre-built algorithms and environments for training and deploying models, as well as tools for managing and optimizing machine learning workflows. AWS SageMaker is used by organizations in a wide range of industries to analyze and gain insights from data, build predictive models, and automate business processes.

A close-up of the different components
Jupyter Notebooks
AWS SageMaker enables users to host Jupyter Notebooks, which are interactive documents that can contain code, text, and visualizations. This makes it easy for data scientists to explore and analyze data, build and test machine learning models, and share their findings with others.
Training & Deployment Tools
AWS SageMaker provides several tools for training and deploying machine learning models, including the SageMaker Studio, which is a web-based interface for managing machine learning projects; the SageMaker Training Service, which enables users to easily train and evaluate machine learning models on large datasets; and the SageMaker Inference Service, which allows users to deploy trained models to perform real-time predictions and inferences on new data.
SageMaker Canvas
AWS SageMaker also includes SageMaker Canvas, which is a visual interface for building, training, and deploying machine learning models. SageMaker Canvas allows users to drag and drop pre-built algorithms and data sources to create machine learning pipelines, and to monitor and debug models as they are being trained.

Specialized Tools & Services
In addition to these core features, AWS SageMaker also offers a few specialized tools and services for specific types of machine learning tasks, such as natural language processing, computer vision, and recommendation systems. These tools and services can help users build and deploy machine learning models more quickly and easily, and with better results.
Why & when should you (not) use AWS SageMaker?
Some PROS of using AWS SageMaker
Ease of use: AWS SageMaker is user-friendly and makes it easy for developers and data scientists to build, train, and deploy machine learning models. MLOps (monitoring, versioning, retraining, testing, …) becomes very simple, because it can all be done in one and the same interface. As also explained above, it is even easy for business analysts to create machine learning algorithms in SageMaker Canvas, without using difficult .
Scalability: AWS SageMaker can handle large volumes of data and can scale up or down as needed to meet the needs of the user.
Integration with other AWS services: AWS SageMaker is fully integrated with other AWS services, such as S3 and EC2, which can make it easier to manage machine learning projects and workflows.
Some CONS of using AWS SageMaker
A cheaper alternative would be to host your own JupyterLab environment, using Tensorflow, which is an open source platform for ML that can be used on-premise or in the cloud. The downside of this approach is that it is less user-friendly and less scalable.
How to get started with AWS SageMaker?
To get started with AWS SageMaker, users will need an AWS account and some basic familiarity with machine learning concepts. Once they have these, they can create a SageMaker notebook instance and start building and training machine learning models using the provided tools and resources.
Let’s do this!
As an example, let’s say that a company is looking to use machine learning to improve its customer service operations. The company has a large dataset of customer service logs, which contains information about different types of customer service requests and their resolution times. It wants to build a model that can predict which customer service requests are likely to be the most difficult to resolve, so that they can prioritize them and ensure that they are handled efficiently.
This is a simple example of a customer service logs dataset:
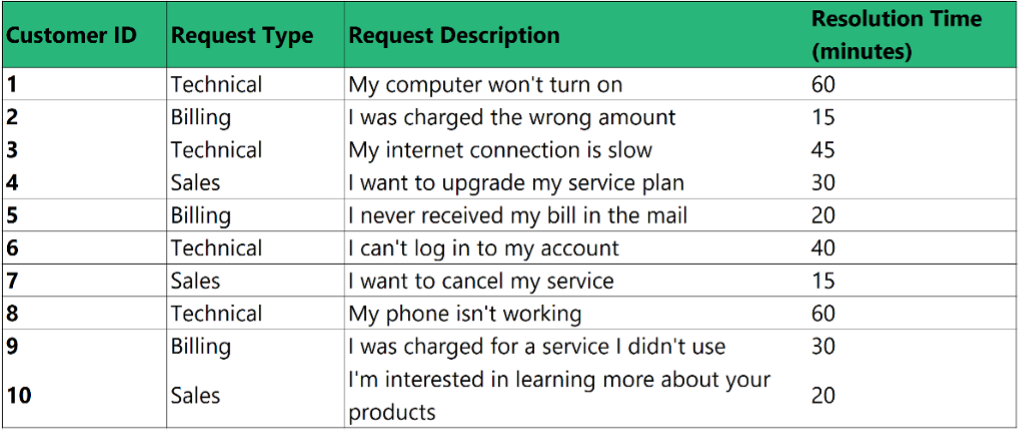
Step 1: Setting up the environment
The first step in this process is to set up the environment for training and deploying the machine learning model. This includes creating an AWS account and a SageMaker notebook instance, as well as installing any necessary libraries and dependencies.

Step 2: Exploring and preprocessing the data
Next, you will need to explore and preprocess the customer service logs dataset. This may involve cleaning the data, imputing missing values, and performing any necessary feature engineering. You can use the Jupyter notebooks feature of AWS SageMaker to perform these tasks and visualize the results.
For example, you can create a histogram to visualize the distribution of resolution times for different request types, or you can also create a scatter plot to see if there is any relationship between the resolution time and the length of the request description.

Step 3: Building and training the model
Once the data is ready, you can use the SageMaker Training Service to build and train a machine learning model on the customer service logs dataset. You can for example use a gradient boosting algorithm, such as XGBoost. This can be a good choice, because it is effective at handling high-dimensional datasets and can handle missing values.
To train the model, you will need to split the customer service logs dataset into a training set and a validation set. The training set will be used to train the model, and the validation set will be used to evaluate the model’s performance during training. During training, you can experiment with different hyperparameter settings, such as the learning rate, to find the best model for the task. You can monitor the model’s performance on the validation set in real-time, and to adjust the hyperparameters as needed to improve the model’s performance.

Step 4: Evaluating the model
After the model is trained, you can use the SageMaker Inference Service to test the model’s performance on a separate test dataset. This will allow you to see how well the model generalizes to new data, and to identify any potential problems or areas for improvement.
Step 5: Deploying the model
If the model performs well on the test dataset, you can then also use the SageMaker Inference Service to deploy the model to a production environment. This will allow the company to start using the model to predict the resolution time for new customer service requests in real-time.
To deploy the model, you will need to create an endpoint using the SageMaker Inference Service. You can then use the endpoint to send new customer service requests to the model and receive predictions back in real-time.
Step 6: Monitoring and updating the model
Finally, you will need to monitor the performance of the deployed model over time and make any necessary updates or improvements to keep it running smoothly. You can use the SageMaker Studio to track the model’s performance, as well as to manage the model’s training and deployment processes.
Conclusion
In this blog, we got to know AWS SageMaker, which features it has and what the pros and the cons are of using it. We saw how AWS SageMaker can be used to build and deploy a machine learning model for predicting the resolution time for different types of customer service requests. For example, the model might predict that technical requests like “My computer won’t turn on” are likely to take longer to resolve than billing requests like “I was charged the wrong amount”.
The AWS platform provides a range of tools and resources for building and optimizing machine learning models, as well as for managing the end-to-end machine learning workflow. By using AWS SageMaker, the company was able to improve its customer service operations and ensure that its customers were receiving timely and effective .
If you’re excited about our content, make sure to follow the InfoFarm company page on LinkedIn and stay informed about our next blog. Interested in how a data platform would look like for your organization? Book a meeting with one of our data architects and we’ll tell you all about it!
Want to start building your own data platform straight away? Take a look at the InfoFarm One Day Data Platform. A reference architecture in both AWS and Azure. We get you going with a fully operational data platform in only one day! More info on our website.