By Vincent Huysmans – Data Architect
Data is, and will always be, very important to us. I think we can all agree on that. However, many companies don’t seem able to set up their IT infrastructure in a way that allows them to get the best insights out of their data. The only way to achieve this, is by having a well-designed data architecture that can deal with the enormous volumes of data that are being generated these days.
Luckily, technological advancements over the last century provide us with a new way of processing data: data streaming.
Ok, I know that streaming is nothing new under the sun. I think we already know what the many advantages of streaming are. Nevertheless, many organizations don’t succeed in implementing this new way of handling data in a correct way. In many cases they are introducing more problems than they are solving.
In this blog I try to shed some light on the properties of a good streaming architecture and why it’s a good idea to start looking at implementing one.
A Streaming-first Data Architecture
In many cases, a traditional architecture is built around decisions where time doesn’t play a crucial or critical role. These systems are what we like to call “batch systems”. Although most of the data is not generated in batch, it still gets processed at fixed time intervals. Time intervals which we are creating in an artificial way.
During this process, we lose some of its value since we are processing data in a delayed fashion. Although batch processing might have been sufficient in the past, nowadays this is starting to cause some problems like complex and slow pipelines. This, in turn, leads to results that are as far from real-time as Internet Explorer’s response time.
Reaction time is key and current streaming technology provides us with real-time processing power. Consequently, organizations should start looking at setting up a streaming-first architecture. This architecture will be able to flow the data past many different systems in real-time.
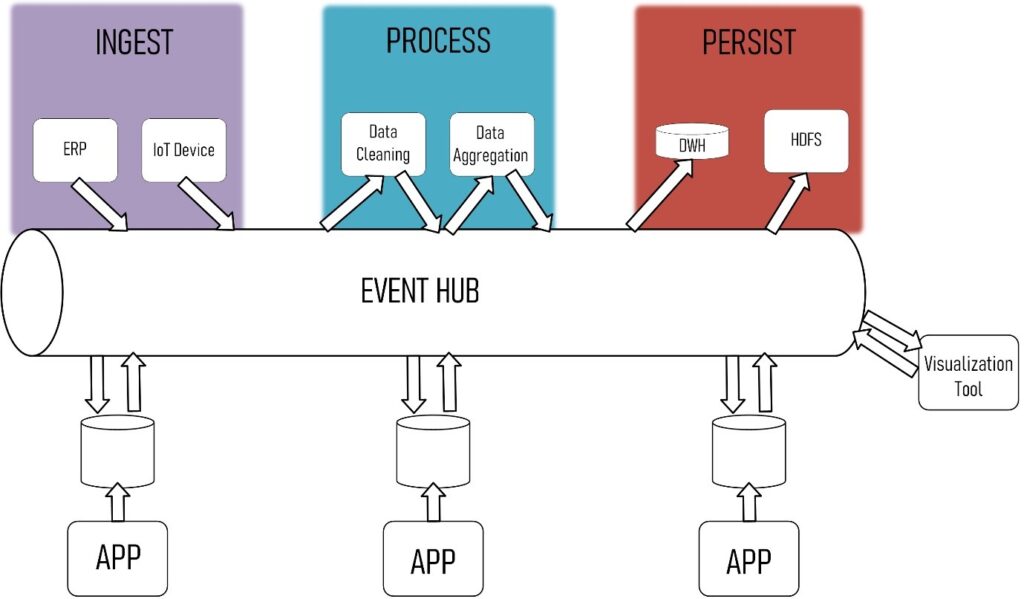
The data is captured, processed and persisted at the moment, or very shortly after, it is generated. No need to artificially add time intervals as we don’t need to bound our data anymore. This way of processing data is a much better representation of the real world and it allows us to interpret our data far more realistically.
When we look at this from a high-level perspective, this data architecture is rather simple to explain. Generally, this kind of architecture consists of different layers. Each layer has its own distinct technology stack specifically chosen for the purpose of the layer (ingest, validation, processing, persistence, …).
Each of these components will be consuming and producing data from and to a stream. This stream is managed by a central event hub, which acts as the transport layer between all the different systems. The event hub is a collection of queues or topics where components can pull data and process it the moment it is available.
Most often technologies like Kafka or ActiveMQ are used for this. Besides processing, other applications for real-time dashboarding can hook into the queue with cleansed and processed data and directly integrate and visualize the information.
More than real-time
Although the real-time aspect is one of the biggest advantages of streaming, it goes a little bit further than that. It offers us more flexibility and the ability to respond faster to data-driven decisions. By decoupling the many sources (e.g. the IoT device) from their targets (the visualization tool), we can plug in any application or system in the current infrastructure at any time. This is the key for flexibility!
Such an approach also clears the path for using concepts like microservices and serverless computing. Both of this step away from the monolithic way of working.
Streaming-first concepts
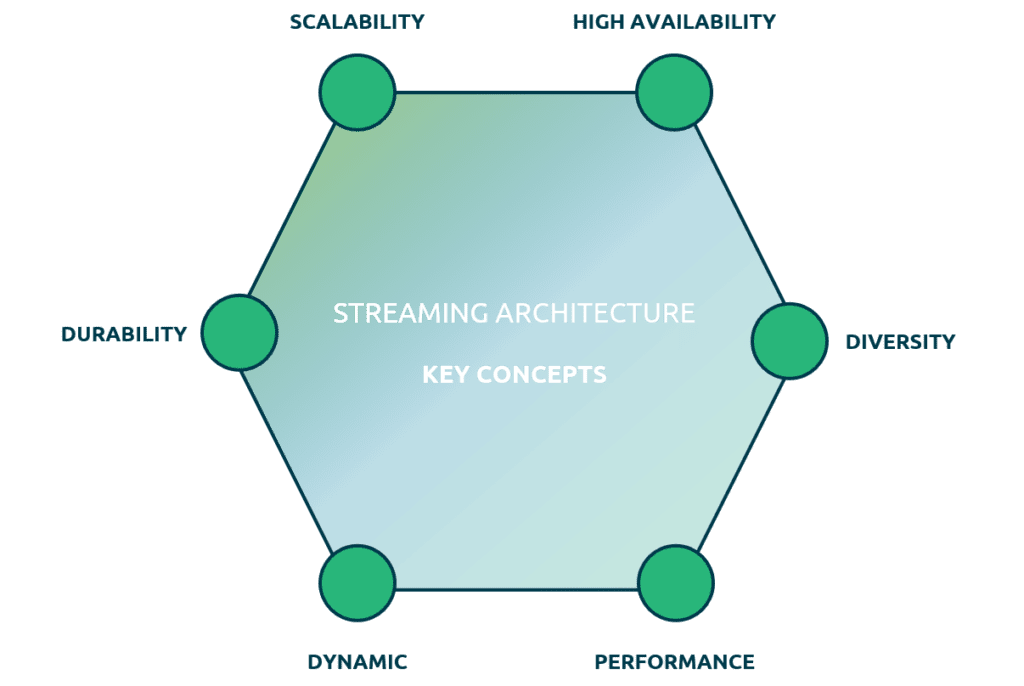
I believe that there are six concepts one needs to consider when building an architecture such as the one described above:
- Scalability: The architecture must be able to adapt to many different sources and high spikes in data volume. Therefore, we need to look at solutions that can easily scale up and down. Vertically scaling by simply adding more CPU and RAM to a single computer system, and horizontally by running in a distributed environment and adding more machines.
- High availability: Applications that process data 24/7 needs to be resistant to network outages and other system failures. So, there must be a recovery mechanism in place that can handle this without losing any data.
- Diversity: When talking about diversity, I’m referring to the huge number of different source and target technologies that are around. Good streaming-first architecture can handle this large variety of technologies or can easily adapt to new ones.
- Performance: One of the biggest advantages of streaming is that it’s fast because it’s real-time. The value of real-time processing fades away when the platform causes delays when processing data.
- Dynamic: Data changes a lot over time. Good infrastructure can handle these changes without having to worry about losing data or impacting other systems.
- Durability: We can start processing the data before persisting it, but we still need to persist to guarantee durability. The architecture will consist of multiple systems which all rely on the data to be ready when needed. We can’t lose data if a downstream system is not finished processing.
Possible Pitfalls
This all sounds very promising, but still, we need to be aware of some possible difficulties along the road to our success in streaming. A couple of these pitfalls could be:
- Joining: Unlike batch processing, streams are unbounded. It is possible that we don’t have all the keysets available from both datasets when joining two streams.
- Data Replay: In case of failures or for historical analytics we need to be able to replay events from a certain moment in time. There is a need for a mechanism that can send these events back passed all the systems in deterministic order until it reaches the tail of the stream. Building and implementing these kinds of mechanisms can be very complex and expensive.
- Memory Management: When processing streams, a sufficient amount of data needs to be available in memory in order to fulfill all the time-based operations (like joins and windows). In some cases, data for an operation needs to be kept in memory for a couple of months. Retaining this data and removing it efficiently can be a difficult task. Therefore, memory management is key.
- The burden of choosing the right technology stack: When setting up a streaming-first architecture, it is important that you choose the right frameworks for the job. There is no single tool that can cover all the different layers of the architecture. Therefore, every task needs to be analyzed in detail so that it can be linked to the appropriate technology. Selecting the wrong technology for a task can rapidly impact the entire infrastructure.
What’s next?
These where the basics of a streaming-first architecture, its concepts and its difficulties. With that covered, we have a good basis for building our streaming infrastructure. Now we can start looking for a good technology stack. In my next blog, I will look at a stream processing technology called Apache Flink. So make sure to keep checking out our website and LinkedIn page.
Do you feel the urge to have a second look at your data architecture after reading this article? Don’t hesitate to contact me directly (LinkedIn) so we can help your business implementing the perfect streaming architecture!