
By Vincent Huysmans – Data Engineer
Hi, vincent huysmans again! In the previous blog, I explained why serverless services are a good fit when building your new data platform. In this blog, I will show you how to build a data platform using a ‘serverless-first’ approach in aws.
Data Platform components
In general, you will need the following functionalities in your data platform:
- Ingestion: a means of getting data in your platform
- Storage: having a simple and secure way to store your data
- Governance: an overview of which data you have and where to find it
- Transformation: transforming the data for your needs
- Analysis & Visualization: exploring your data, building reports, and doing machine learning
- Orchestration: Tying everything together in a streamlined workflow
How can Amazon Web Services help?
AWS (Amazon Web Services) offers us a variety of services to help setup our serverless data platform. The purpose of this topic is to categorize the most common serverless services needed for the data platform based on the different data responsibilities.

1. Data Ingestion
Amazon Kinesis Firehose – Service that is part of the Amazon Kinesis collection used for loading real-time streams of data into the data lake or connecting directly to other analytic services.
API Gateway – API Gateway is a service that is used for managing and maintaining APIs. An API can be used for ingesting smaller datasets coming from mobile applications, or other services within your data platform. It integrates seamlessly with other AWS services, like Lambda, Kinesis and Step Functions.
AWS Lambda – Is an event-driven computing service that is completely serverless. As a developer you just have to provide your code and the service will take care of underlying infrastructure. Due to Lambda’s architecture, it has its limitations for data ingestion and data transformations. I would advise using AWS Lambda as data ingestion tool in combination with API Gateway to upload small files to S3. Or, if you are copying data that is already present in your cloud environment and you want to ingest it into your data lake. In that way you can ingest the data using the AWS SDK, so you don’t need to load in all the data and you don’t need to worry about any disk space limitations.
AWS Glue – AWS Glue is a fully managed serverless ETL service. It provides both visual and code-based interfaces for creating your ETL jobs. The Glue ETL jobs can be compared to Lambda functions but with the difference that Glue is more focused on (big) data processing. Meaning it eliminates the limitations that AWS Lambda has concerning disk space and runtime. Glue can be used on the ingestion layer as well as on all the other layers of your serverless data platform. It can integrate with numerous of sources to ingest data from AWS services or other data providers outside of your cloud environment.
2. Data Storage
Amazon S3 – For your serverless data platform the most sufficient serverless storage service will be Amazon S3. This is an object storage service that offers industry-leading scalability, data availability, security, and performance. Although there are other serverless storage services, we think that S3 covers most of the use cases for your applications because it can be used to store both raw and processed data. If there is a specific use case where you would need to use services like Aurora (SQL), DynamoDB (NoSql), or Redshift Serverless (data warehouse), you can still use it running side-by-side with S3.
3. Data Catalog
AWS Glue Data Catalog and crawlers – To create a data platform, you must catalog your data. AWS Glue Data Catalog is used as a location for referencing your data. It consists of metadata tables with indexes to locations, schema information, and additional metrics of your data.
Typically, to get this information in your catalog, you would need to run Glue Crawlers. These are small configurable applications that you can create, schedule, and run. They will take inventory of the data in your data store and save the data in the metadata tables.
4. Data Transformation
AWS Glue – Using the Glue ETL jobs, you can easily transform and load your data in S3. With Apache Spark under the hood, Glue is specially designed for processing large amounts of data. If you are preforming complex transformation on larger datasets, I would advise to use AWS Glue as your serverless option for data processing in AWS.
AWS Lambda – If you want to perform transformations or enrichment on small batches of data, setting up a Glue job can be an overkill and will result in an unnecessary high cost. For those cases you can use AWS Lambda.
5. Data Analysis
Kinesis Analytics – Amazon Kinesis Analytics is probably the simplest way to analyze your streaming data. It uses Apache Flink under the hood (please use my blog about Apache Flink as a reference) to continuously transform and analyze data using languages as SQL, Java, Python or Scala. You can also analyze the streaming data using managed Apache Zeppelin notebooks with Kinesis Data Analytics Studio.
Athena – Amazon Athena is a serverless interactive query service to analyze big data stored on S3. It is fully managed as you will only need to provide your SQL query (Presto) to analyze the data. The charges are based on the amount of data scanned.
QuickSight – Amazon QuickSight is a cloud-scale business intelligence (BI) service that you can use to deliver easy-to-understand insights to the people who you work with, wherever they are. Amazon QuickSight connects to your data in the cloud and combines data from many different sources. In a single data dashboard, QuickSight can include AWS data, third-party data, big data, spreadsheet data, SaaS data, B2B data, and more.
SageMaker – Amazon SageMaker is a fully managed machine learning service. With SageMaker, data scientists and developers can quickly and easily build and train machine learning models, and then directly deploy them into a production-ready hosted environment. It provides an integrated Jupyter authoring notebook instance for easy access to your data sources for exploration and analysis, so you don’t have to manage servers.
6. Data Orchestration
Step Functions – AWS Step Functions is a service that lets you build workflows consistent of multiple AWS services, such as the one described above. A workflow consists of different steps with each step performing a single task. With this service you can chain different Glue ETL Jobs and Lambda Functions together to setup an entire ETL flow for a single data source.
AWS Glue Studio – Since 2019, it is also possible to setup workflows in AWS Glue. Workflows enable orchestration of your ETL workloads by setting up dependencies between all the different Glue entities (triggers, crawlers and jobs). The downside of this feature in comparison with Step Functions, is that it can only be used to orchestrate Glue components. If your workflow requires running a Lambda function, I advise to use Step Functions instead.
Putting everything together: an example architecture
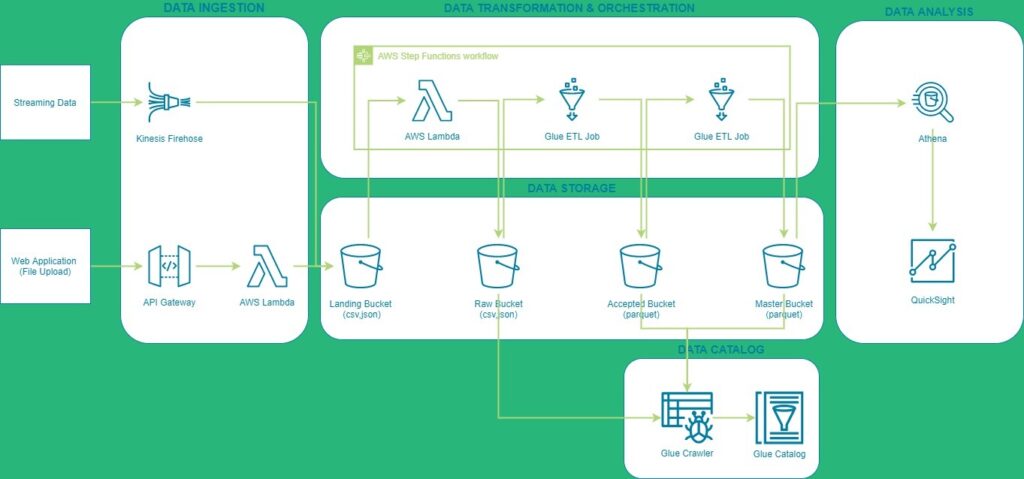
We have data coming in from a streaming source and files being uploaded via a web application. We use Kinesis Firehose, API Gateway, and Lambda to ingest data into the data lake.
The first S3 bucket in the storage layer is the landing bucket. This bucket contains all the data in the rawest form, and acts as a temporary storage for all data coming in the data lake. Each day a Step Functions Workflow is triggered containing three steps:
- Lambda function for copying and partitioning data from landing to raw bucket
- Glue ETL Job for cleaning and repartitioning the data to the accepted bucket
- Glue ETL Job for transforming the data to the master bucket
All the metadata for the different storage buckets (starting from raw) is fed into the Glue Catalog daily by the Glue Crawlers.
Once all data is processed and catalogued, we can use Athena to analyze the data by performing SQL queries. And use the Athena connector to create dashboards using QuickSight to get more insights in your data.
That’s it for this week’s blog. Next week we will take a closer look at cloud data platforms build with Microsoft Azure components. If you’re excited about our content, make sure to follow the InfoFarm company page on LinkedIn and stay informed about the next blog in this series. Interested in how a data platform would look like for your organization? Book a meeting with one of our data architects and we’ll tell you all about it!
Want to start building your own data platform straight away? Take a look at the InfoFarm One Day Data Platform. A reference architecture in both AWS and Azure. We get you going with a fully operational data platform in only one day! More info on our website.
