By Vincent Huysmans – Data Architect
In my previous blog I covered the basics for building a streaming-first architecture. We’ve discussed how streaming could be the next data processing paradigm, as compared to batch processing. This follow-up blog will be a little more technical as I will be discussing Apache Flink, a stream processing technology.
Data processing with Apache Flink
Processing data in a streaming architecture has always been a challenge. More often than not, a stream of data gets bounded by an artificial start and end. A stream does not have an ending, and by defining one, we lose essential value from our data.
Additionally, processing pipelines become very complex in terms of development and maintenance, especially when we look at the large volumes of data that are generated these days. Luckily with the rise of many streaming technologies, built specifically for handling these tasks, we can now process and analyze streaming data a lot easier.
Today we already have a great set of technologies that fall into this category. Think of technologies like Apache Storm, Apache Spark Streaming, Kafka Streams (Apache Kafka), or Apache Apex. Each of these technologies has its advantages as well as its disadvantages, and each of them can be used for different use cases.
The technology that will be covered in the blog will combine a lot of the advantages of the above technologies while eliminating some of their drawbacks.
| Technology | Drawback(s) |
| Apache Storm | · More difficult to use
· No out-of-the-box event-time processing |
| Apache Spark Streaming | · Based on the micro-batch model
· Higher latency |
| Kafka Streams | · Limited to Kafka sources and sinks
· Only unbounded streams · Not designed for heavy lifting work |
| Apache Apex | · Not widely used, smaller community
· Limited SQL support |
Apache Flink is an open-source framework with a distributed engine that can process data in real-time and in a fault-tolerant way. Real-time when talking about Apache Flink is actual real-time, as opposed to Apache Spark, where streaming is actually a series of micro-batches. Wherewith Spark everything is a batch, in Flink, everything is a stream. Even when we batch process we’re actually using a stream.

Flink programs are represented by a data-flow graph (i.e., directed acyclic graph – DAG). The data flow graphs are composed of stateful operators and intermediate data stream partitions. The execution of these operators is handled by independent task slots on multiple machines in a cluster. These task slots execute their tasks in parallel and in-memory, so processing can be done within milliseconds.
In essence, each Flink application will take data from a stream, perform operations in parallel to transform the data, and finally write the transformed data to a data store. These steps will be executed in a continuous stream.
What really makes Flink an excellent processing tool for a streaming-first architecture, are its different concepts. It’s not my intention to dive deep into technical details here, but merely give a high-level overview of why these concepts are important in a streaming-first architecture.
Streams
It speaks for itself that the concept of streams plays an important role in a streaming architecture. This concept can be approached in two ways: bounded and unbounded streams. Both ways can be processed by Flink.
Unbounded streams are streams for which we don’t know in advance when they will end. The stream is not split up in small batches but is continuously processed. Flink cannot wait for all the data to be ingested before starting processing because it doesn’t know when all the data should be read in.
This means that all the data will be processed almost immediately when it’s ingested. Often these kinds of data streams require the data to preserve the order of creation, which can affect the correctness of the result.
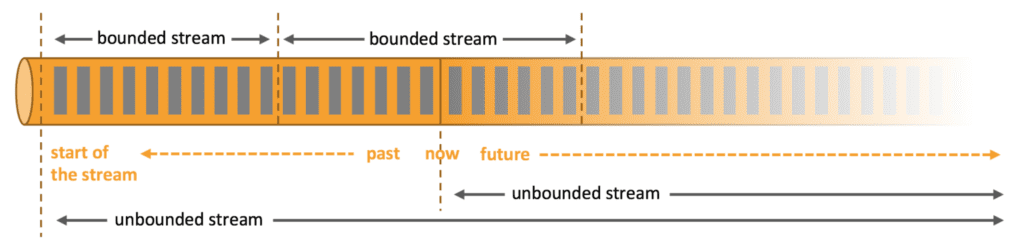
A bounded stream does have a defined ending. This concept enables Flink to read in all the data before starting to processing it. The ingestion order here is not that important, as the data can always be sorted after it’s been loaded.
Being able to process data as an unbounded stream makes Flink already a very interesting tool for a streaming-first architecture. Data does not need to be divided into micro-batches as it does in many other processing technologies. It takes over the natural flow of the data and makes the processed data available almost instantly after ingestion.
Time
A second very important concept in streaming is time. In most cases, data streams have a time label, and in most cases, this label indicates the point in time when the event was created. Also, the processing of streaming data is in many cases time-based, such as applying windows, time-based joins, sessions, …. Flink can measure this time in different ways, where it can distinguish between event-time (moment in time when it was created) and processing-time (moment in time when it gets processed).
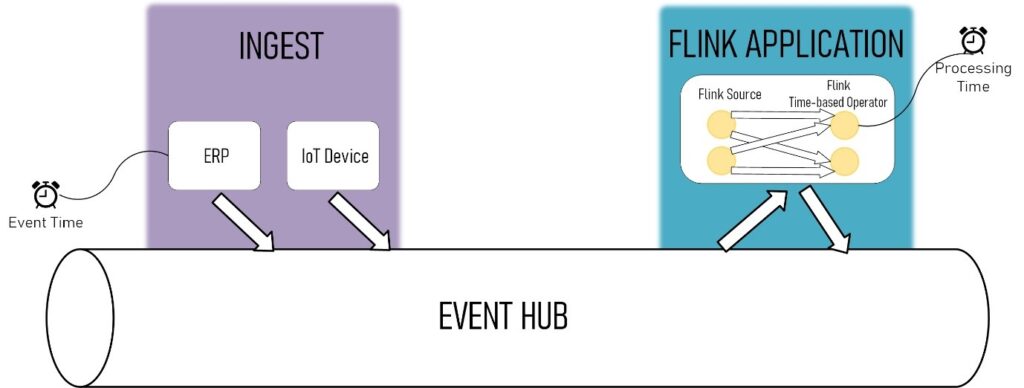
Many other technologies manage to handle data on processing time, which is good for low-latency requirements but not so much when we need a 100% correctness of the result. Handling data based upon the time it was created is a little bit harder, and many technologies don’t offer this option. The good thing about Flink is that it can handle both, offering the platform to meet the low-latency requirements as well as correctness.
State & Fault Tolerance
In a lot of cases, we need our streaming applications to hold some kind of state. This state is a critical aspect of the streaming platform. There is a need for a mechanism to pass a certain result between different operations across multiple events. We don’t want to forget this result when a certain event is processed. These operations are called stateful.
In case of failure, we need to be able to recover the state, but also be able to roll back to simulate a new failure-free execution. Building your own mechanism for handling this is very complex, expensive and time-consuming.
Fortunately, Flink can do this with a built-in checkpointing mechanism. When enabled, this mechanism draws consistent snapshots of the data stream and state. These snapshots act as consistent checkpoints to which the system can fall back in case of a failure.
These built-in features for fault-tolerant state are one of the many advantages of using Flink as processing tool for our streaming architecture.
Exactly once delivery
The above features enable Flink for an exactly-once delivery of an event. This means that an incoming event affects the result just once. No events get duplicated and no event remains unprocessed, even in case of failure.
This concept, like the ‘event-time mode’, adds up to the correctness of the result. In most cases, there are explicit requirements that need to be met by the output. Flinks exactly-once delivery only finishes the processing of an event when it conforms to the output requirements.
What’s next?
This was a theoretical overview where I talked about Flink in general as well as the basic concepts and why they are important in a streaming-first architecture. We just scratched the surface with this, and there is a lot more to discover when using Apache Flink.
In my next blog, I will clarify the Flink concepts a little bit more by working out a practical example. So make sure to keep checking out our website and LinkedIn page.
Did this blog convince you to start working with Apache Flink? Don’t hesitate to contact me directly (LinkedIn) so we can help your business implementing the perfect streaming architecture!