
By Seppe van winkel – DATA ENGINEER
Hi, my name is seppe van winkel, data engineer at infofarm and I’m taking over the blogseries about cloud data platforms this week! In our previous blog, my colleague vincent explained the aws serverless architecture. In this blog, I’ll show you the azure counterparts. How can we build a data platform out of azure cloud services? Which data services exists and what are our best practices? All answers below. Enjoy reading!
How can Azure help?

Microsoft Azure is a cloud platform and contains more than 200 products and cloud services designed to help you bring new solutions to life. The purpose of this topic is to give you a brief overview of the most used serverless data services.
Overview of the Azure Serverless Data services
We’ve split up the services in their respective categories, we’ll cover compute, storage, monitoring, streaming, data & AI, visualization and supporting services. Later in the blog, we will put everything together and create one Azure cloud data platform.
Compute

Azure Functions – An Azure function is a serverless compute service. It allows the user to run event-triggered code without the hassle of the infrastructure. It allows users to write code in several languages, containing Python and C#. By default, a function cannot run for more than 5 minutes. But if you really need to execute a long running task, there are some patterns that allow for function chaining or orchestration.
Functions are event-triggered, this means you can attach events towards the function. These events can be sent by a lot of the services of Azure. For example, you want to move newly uploaded files to the correct folders then you can easily write a function that will trigger “file upload” and will execute said action.
Storage

Azure SQL – The Azure SQL family is a big collection of possibilities that allows you to run SQL in the cloud. Most important parts of this family that we focus on today are the serverless parts. Creating a single database that allows you to scale or multiple databases that are running on a scalable pool. It is all possible.
SQL stands for Structured Query Language. This means it has a structured schema containing the columns and its data types. It is mostly used for relational data.

Azure Cosmos DB – Azure Cosmos DB is a fully managed NoSQL database. The ‘counterpart’ of the Azure SQL. The Azure Cosmos DB has different API’s that allow querying with different tools. There are API’s available for SQL, Cassandra, MongoDB, Gremlin and Table Storage.
NoSQL is of course the counterpart to SQL, some of the use cases that could lead to NoSQL are hierarchical data, complex networks & relationships, and a fluid schema.

Azure Storage – Azure storage is a massively scalable and secure storage for cloud purposes. Azure storage is divided in five parts. The main component, being a ‘storage account’, is a wrapper for all the underlying services:
> Blob Storage – Blob storage or object storage is optimized for storing massive amounts of unstructured data in the cloud. This means you can upload everything in here: files, photos, videos, etc. Inside the account you will make a container to store the data. Inside the container it will allow you to upload everything to a maximum of 5 PB (Petabyte) with each file being a maximum of 4.75 TB (Terabyte). 5 PB is a lot, roughly 1050 million songs.
A Blob storage account has a lot of features that allow it to be a robust solution for storing data. Features like but not limited to soft-delete, versioning, encryption. It also features different access tiers to keep costs down. By default, everything will be ‘Hot’, this means that it has the highest storage cost but the lowest access cost. The second tier ‘Cold’ is for data that is infrequently modified or accessed and has lower storage cost but higher access costs.
Finally, for data that is rarely accessed, there is one more tier left: ‘Archive’ which has the lowest storage costs but can’t be accessed in real time. It takes time to make it available which can take up to 15 hours.
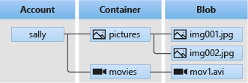
> Data Lake – We also have the Data Lake, which is the same as the above but with a different option. Enabling a storage account with hierarchical namespaces. This will gain some functionality like an actual folder structure and more fine-grain AAD (Azure Active Directory) access control at directory level.
But some features that Blob storage has, will be lost. Because they are not supported yet. The missing features are versioning, object replication for blocks and point in time restore for blocks.
Azure is continually working on adding all the existing features to the Data Lake. The remaining missing services are not that important for most of the data platform and are more for specific use cases. That’s why we recommend using Data Lake of a normal Blob Storage.
> File Shares – File Shares are fully managed file shares in the cloud that are accessible via the standard SMB or NFS protocols. File shares can also be mounted in other services. For example, you can mount a file share to an Azure Function.
> Table Storage – Table Storage is a service that stores non-relational structured data. Essentially it is a key/attribute storage that allows you to adapt the data easily as the needs evolve. It is fast and cost effective.
> Queue Storage – Queue Storage is a service that allows you to store many messages. Queues can contain messages up to 64 KB each until the storage limit is reached. Queues can be used to do work asynchronously.
Monitoring

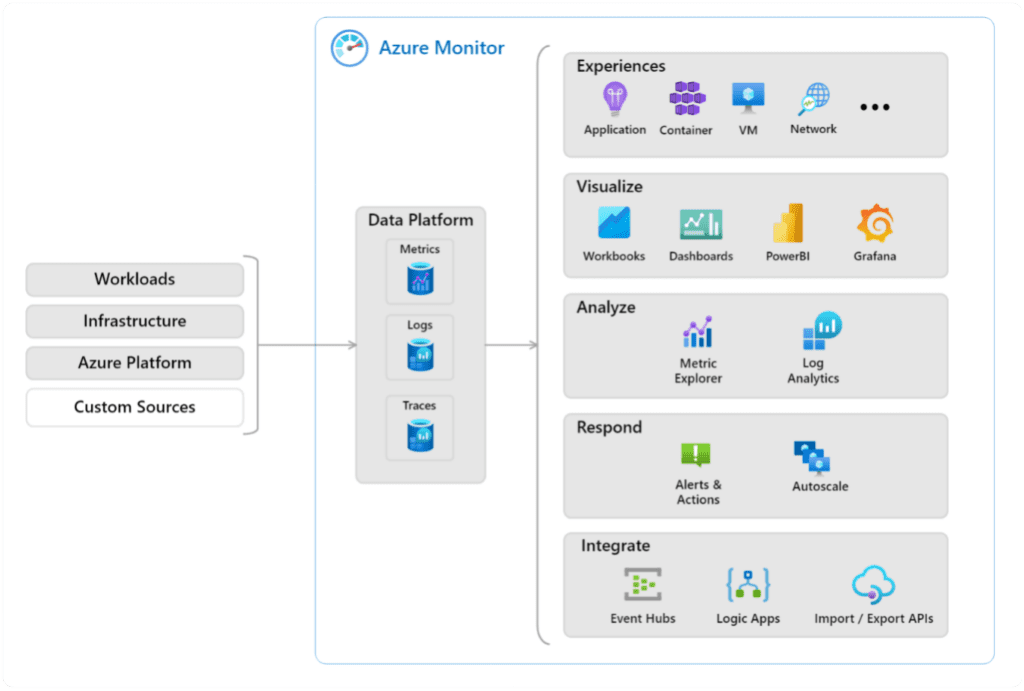
Azure Monitor – Monitor collects monitoring telemetry from all the serverless services. It will give you insights in availability and performance. It will contain all the logs that are being written inside. Monitor will allow you to visualize all this telemetry, but also to respond on the incoming telemetry. You can set alerts and actions on certain thresholds but also scale some existing applications to allow more throughput.
Streaming

Azure Event Hubs – Azure Event Hubs is a big data streaming platform and event ingestion service. It can receive and process millions of events per second. Data sent to an event hub can be transformed and stored by using any real-time analytics provider or batching/storage adapters. It is also compatible with Apache Kafka.

Azure Stream Analytics – Stream Analytics is a stream processing engine that is designed to analyze and process large volumes of streaming data. It allows you to identify patterns and relationships in data that can come from various sources.
Data & AI/ML

Azure Cognitive Services – Cognitive Services is a service that will allow you to build cognitive intelligence into your application. It allows people without AI or data science skills to use these features. You can utilize this service to build solutions that can see, hear, speak, understand, and even make decisions.

Azure Machine Learning – The Machine Learning is a service that accelerates and manages a machine learning lifecycle. It allows you to train and deploy models and manage your MLOps. You can create a new model or use a model from an open-source platform such as PyTorch, TensorFlow, etc.

Azure Synapse – Azure Synapse is a limitless analytics service that brings everything together. It can ingest, explore, prepare, transform, and serve data for immediate BI and ML needs. Synapse contains possibilities for serverless SQL pools, but also for serverless Spark pools that can be used to execute your notebooks. This makes the service multifunctional it will allow you to query files through SQL, allows you to prototype using notebooks, allows you to create data flows and speak to different services.
Visualization

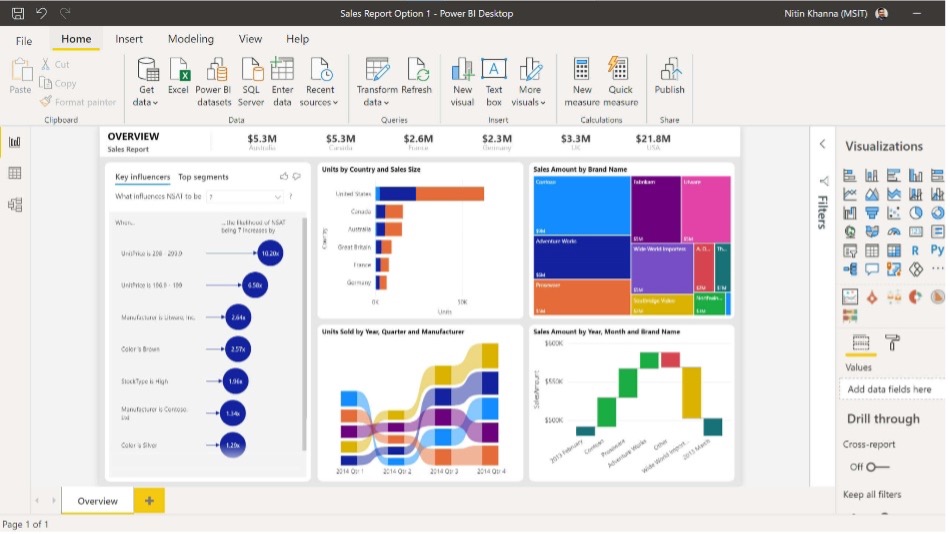
Power BI – Power BI allows us to connect all the data we get from Azure, either from a storage account, a database or from Azure Monitor. Power BI allows you to create dashboards and reports and allows everyone, from developers to business users, to get insights in their data.
Developer Tools & Supporting services

Azure Key Vault – Every development environment has secrets. Secrets or certificates should be stored properly inside a secure vault. That’s where Azure Key Vault comes in. Key Vault will store everything and allow you to control the user rights with Azure Active Directory. Most Azure services can read from the Key Vault to use their secrets in their workflow.

Azure DevOps – Azure DevOps is the strange duck in this overview. It is often forgotten but it’s a key part in a lot of development environments. Azure DevOps provides developer services for allowing teams to plan work, collaborate on code development, and build and deploy applications. Some of the most important components:
> Azure Repos – Provides Git repositories or Team Foundation Version Control (TFVC) for source control of your code.
> Azure Pipelines – Provides build and release services to support continuous integration and delivery of your applications.
> Azure Boards – Delivers a suite of agile tools to support planning and tracking work, code defects, and issues using Kanban and Scrum methods.
Putting everything together: an example architecture
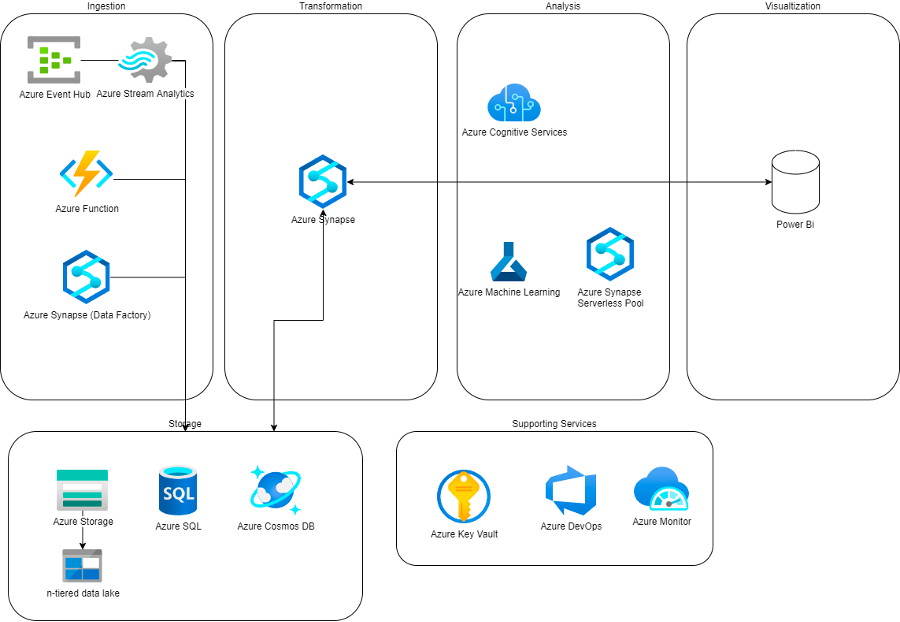
Now we have an overview of all different services, let’s start combining everything into a useable Data Platform. We can combine all functionality in a couple logical sections: Ingestion, Storage, Transformation, Analysis and Visualization.
Ingestion
Usually, your sources are either Files, Databases, APIs or Streaming data sources.
Files can be dropped directly into Azure Storage by the source, or we can fetch it from the source by using an Azure Function. Databases can be queried and ingested using Azure Data Factory – within Azure Synapse. APIs will be consumed using Azure Functions. And Streaming data sources can be ingested using Azure Event Hub.
Storage
All ingested data is stored in the Data Lake using Azure Storage. For faster querying and specialized use cases, processed data can be stored in an Azure SQL DB or Azure Cosmos DB.
Transformation
The beating heart of our Azure Data Platform is Azure Synapse. It will allow us to:
- create triggers that run based on certain time or on certain action;
- transform the data or prototype it using notebooks and data flows;
- quickly view some analytics by querying our files by using the built in serverless SQL pool, this allows you to query the files using SQL.
Analysis
All the data in the Lake can be queried using Azure Synapse Serverless SQL pools. We can also start Notebook Instances from within Synapse to do more in-depth analysis of the data.
Realtime analysis on streaming data sources is possible through Azure Stream Analytics
And for advanced Machine Learning needs, Azure Machine Learning is our go-to tool. Azure Cognitive Services offer some pre-trained models for us to use.
Visualization
For all our reporting and visualization needs, Azure Power BI is the tool we all know and love.
Supporting Services
We will monitor the performance of the platform and our jobs using Azure Monitor. Those jobs will be deployed and versioned using Azure DevOps. And Azure Key Vault helps us in keeping everything secure.
That’s it for this week’s blog. Next week we will take a closer look at the differences between cloud data platforms build with AWS and Microsoft Azure components. Which criteria determine the choice for one of the two different cloud services?
If you’re excited about our content, make sure to follow the InfoFarm company page on LinkedIn and stay informed about the next blog in this series. Interested in how a data platform would look like for your organization? Book a meeting with one of our data architects and we’ll tell you all about it!
Want to start building your own data platform straight away? Take a look at the InfoFarm One Day Data Platform. A reference architecture in both AWS and Azure. We get you going with a fully operational data platform in only one day! More info on our website.
