By Peter Ralston – Cloud Data Engineer
In our previous blog, we wrote about the importance of data ingestion, the different types of data sources and how to use them. In that blog many azure services were mentioned, including azure synapse analytics. The focus of this blog will be to dive deeper into this specific azure service, give a short overview of how it is most useful and give a quick comparison to azure databricks.
Overview
Azure Synapse Analytics is a Microsoft solution for both big data analytics, using spark, as well as data warehousing, using SQL.
Storage
Without storage, we cannot have a data platform and thus no big data analytics. Azure Synapse adds direct integration of the storage explorer without the need for connection strings or local tools. This increases ease of use when browsing through the data lake for business users, analysts, and data engineers alike.
Being able to see where the files are located is nice. However, we also need a way to query this data. With Synapse, this can be done using either a dedicated or serverless SQL pool or Apache spark. In short, Azure Synapse Analytics turns a data lake with files (e.g. parquet or csv files) into a database where we can easily read and analyze data at scale. Note that users are charged by amount of data queried. This means that for very large datasets, it is better to use a columnar file format since querying a single column does not require processing the entire file.
Orchestration
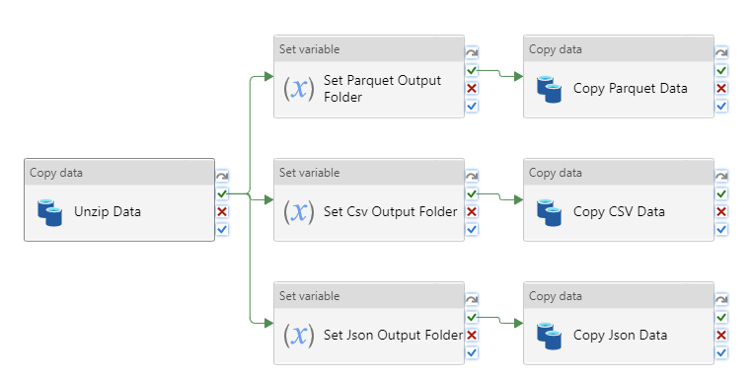
If it works don’t fix it. For those who are familiar with another Azure service named Azure Data Factory, this section will be familiar. In essence, Azure Synapse Analytics recycles the orchestration functionalities which were already present in the Azure Data Factory.
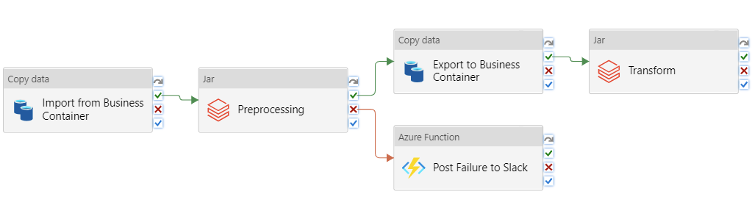
The orchestration is set up with pipelines which contain different Activities. These pipelines can be developed using an easy to use drag and drop tool. Many of the pipeline requirements such as ingestion from any source, orchestrating spark jobs or retraining ML models can be fulfilled using the built-in activities. This makes the pipelines easy to set up and maintain. However, experience has shown us that it is not always possible to rely on the built-in Activities. In these cases, we can write our own custom functionality within an Azure Function and call this using the Azure Function Activity.
Azure Synapse vs. Databricks
As we described the functionalities of Azure Synapse, the question may arise how it differs from Azure Databricks. Indeed, both these services can be used for the purposes of big data analytics and orchestration of pipelines. However, a good rule of thumb is that Azure Synapse is geared more towards a less tech savvy audience, while Databricks requires a high amount of technical prowess to master and more maintenance. One advantage of Azure Synapse is that many profiles within your organization can leverage this service to manage your data.
Moreover, since Synapse pipelines can also orchestrate Databricks Activities it can be useful to combine the two. In short, both have their place in a modern big data architecture on Azure.
Azure Synapse Costs
As mentioned in the sections above, Azure Synapse often focusses on ease of use. This means that there are a lot of low-code solutions like data pipelines and data flows, which allow for low-code parallelize operations. We find that these low-code solutions can often make it more complicated to get an overall view of the costs. Without a good understanding of precisely how Synapse is billing works, we may accidently be paying much more than expected.
Let’s give an extreme example. When using Azure Synapse Data pipelines, it can be very tempting to use the built-in copy activity to integrate and move all your files in an automated manner. For a few large files, this can be great. However, let’s say we have 100 small tables of flight data with five locations that are dropped into a single folder. Then, at the start of each working day, we would like to copy these files in a way so that they can be easily used by our Spark application. Thus we choose to partition these files by year, month, day, and the location of the airport. For this we set up a pipeline that copies each table in this folder in parallel with a copy data activity from Azure Synapse.
Here is the problem, if you’re not able to copy these files in a single activity, but rely on a different activity per table, then each time this pipeline performed you call 100×5 copy activities. Running this each day for a month means 30x5x100 activities.
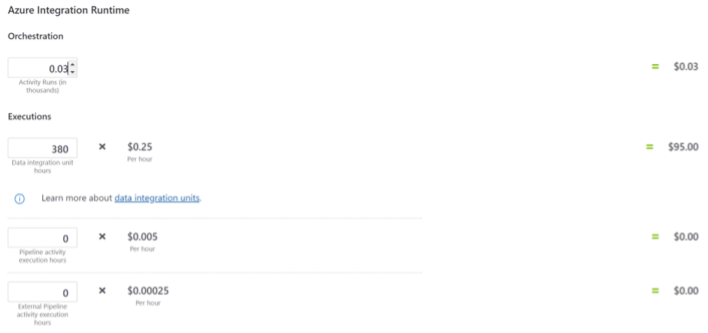
However, under the hood Azure Synapse is billing you based on the number of DIU (Data Integration Unit) and execution duration at $0.25/DIU-hour. This may not seem like much but remember that we are running about 30*5*100 activities a month, so, if every activity is taking one minute, then this could be $250,00 a month just to copy some data!
In general, we have found that it is not always straightforward to control the costs of your Azure Synapse Analytics workspaces, so we suggest implement high-code solutions whenever possible and call these using for example Azure Function Activities. Also, before any pipeline is put into production, estimate the price using the ADF pricing calculator.
Conclusion
To conclude, there is a trade-off to consider when using Azure Synapse pipelines. If you’re not in the position to hire an experienced data engineer (we are a rare breed nowadays) not all is lost. You can still build your fancy data pipelines in a low-code manner. However, take into account that – in general – the running cost of such low-code pipelines tend to be higher than for heavy-code implementations.
For more details on controlling the cost of pipeline see the following azure documentation: https://learn.microsoft.com/en-us/azure/data-factory/plan-manage-costs
When this does look a bit overwhelming to you, or if you don’t want to spend a lot of time setting things up from scratch, do not despair! Take a closer look at the InfoFarm One Day Data Platform. A reference architecture in both AWS and Azure. We get you going with a fully operational data platform in only one day! More info on our website.
If you’re excited about our content, make sure to follow the InfoFarm company page on LinkedIn and stay informed about the next blog in this series. Interested in how a data platform would look like for your organization? Book a meeting with one of our data architects and we’ll tell you all about it!
