By Seppe van Winkel – Cloud Data Engineer
Hi, my name is seppe van winkel, data engineer at infofarm and I’m taking over the blogseries about cloud data platforms this week! In our previous blog stories, we already explained what a data platform looks like. We also talked about all the advantages of a platform as well as the characteristics of amazon web service (aws) and microsoft azure. In this blog, we will dive into the data ingestion part and tell you how to get the data in your platform.
Importance of Data Ingestion
These days, we can’t ignore the amount of data we produce and that could be collected by companies in any type of industry. A data platform could help to get quick insights and maximize performance in your business and its resources.
Before we can start using the data, we need to get the data in our platform of course.

The diagram above shows the different components that are used to build a data platform. In the following blog stories, we will cover the other components such as storage, processing, and data consumption (querying and visualization).
The data ingestion component is responsible for collecting data from different types of resources such as IoT devices, data lakes, (web) applications and so much more. The data will be stored in a data platform. Knowing the size and complexity of the data, is critical to choose to the right cloud architecture.
As mentioned earlier in this blog post series, Azure offers a variety of service to help you set up a serverless data platform. We will look at different services to tackle four common types of data sources: manual file drops, API endpoints, streaming data, and databases.
In the following sections, we will take you through the data ingestion journey and reveal all the Azure services that can be used for this job.
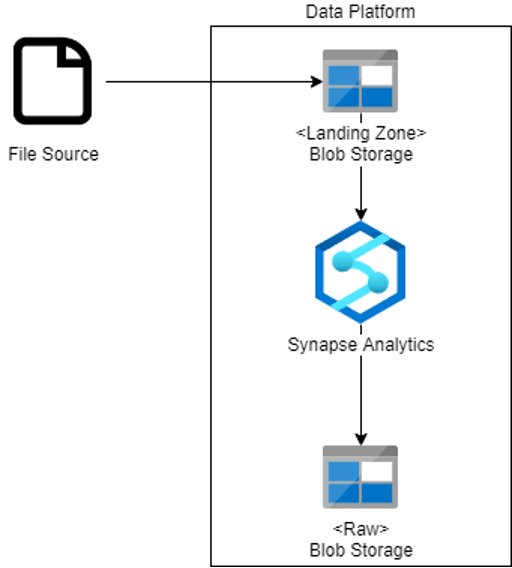
File as Data Source
In Azure, files are stored inside storage containers. This object storage system allows you to save objects or sync files in containers. Depending how often you will retrieve the data, you can opt to choose a less expensive storage tier in Azure.
You can set up a ‘Landing’ zone container. Here you can upload files to be automatically picked up and moved into the data platform. This can be done by using a Synapse Analytics pipeline, or even a Function.
For example, you can create a trigger that executes the Synapse Analytics pipeline for each file that is uploaded to the ‘Landing’ zone container.
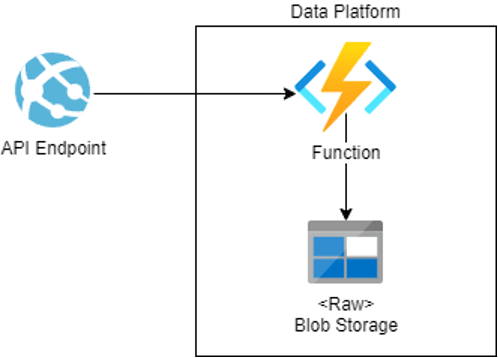
API Endpoint as Data Source
A landing zone is an easy solution for some manual files that are still being used. But honestly there are better ways. It is possible to get data out of APIs either from your own custom APIs or from specific APIs provided by your vendors.
We can capture the API endpoint by using an Azure Function with a timer trigger. The function will capture the data at a certain time and partition it in the right folder on the data lake. Ready for processing.
For example, you are using a specific accountancy solution which exposes certain endpoints for you to get a better financial overview. You want this data to be stored on the data platform. This way you will be able to create better dashboarding. The Azure Function will query the API every night at 03:00. It will capture the data and store it in the data platform so it can be processed.
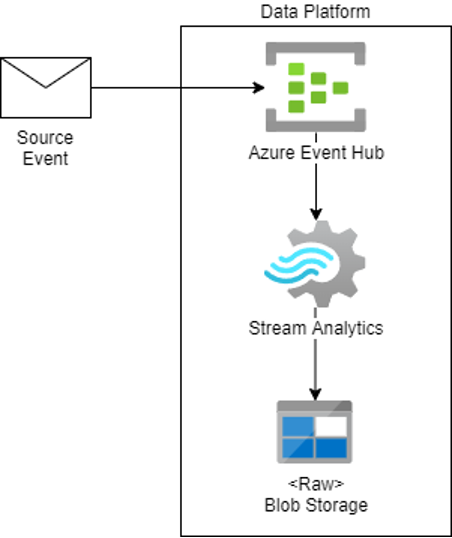
Streaming as Data Source
If you need to collect real-time streams of data into the platform, Azure Event Hub can help you out. It‘s a fully managed service for delivering data directly to a data platform and data stores.
For specific use cases, Stream Analytics can be a useful addition to your streaming architecture. For example, when you want to perform real-time data analytics on data coming in via event streams.
Suppose you are a package delivery company that will deliver millions of packages daily. Every single time a package gets scanned, you will know where that package is. All that data will come into the Event Hub as events and then get stored onto the Data Lake.
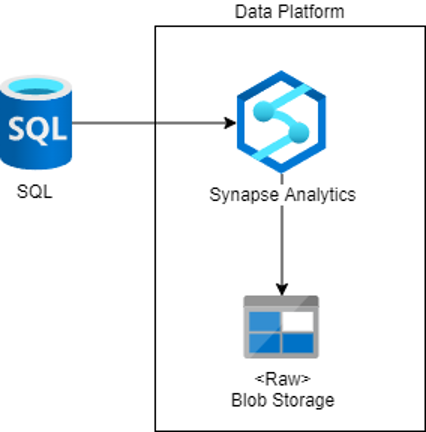
Database as Data Source
Lastly, we have databases, more specific CDC (change data capture). This feature is specifically supported by all Azure SQL instances.
Change data capture allows you to only ingest the new, updated, or deleted records from the timespan you specified. By using the CDC feature inside the Synapse Analytics pipeline, you can query the data and store it to the data platform.
For example, you have a database with sales data and you want an overview of sales. The pipeline can do the CDC check every hour to see what has been modified inside the database. Then proceed to store it inside the platform for further use.
If you’re excited about our content, make sure to follow the InfoFarm company page on LinkedIn and stay informed about the next blog in this series. Interested in how a data platform would look like for your organization? Book a meeting with one of our data architects and we’ll tell you all about it!
Want to start building your own data platform straight away? Take a look at the InfoFarm One Day Data Platform. A reference architecture in both AWS and Azure. We get you going with a fully operational data platform in only one day! More info on our website.
