By Olivier Jacobs – Cloud Data Engineer
Welcome back to the blog! In our previous blog stories, we already explained what a data platform looks like. We also talked about all the advantages of a platform as well as the characteristics of amazon web service (aws) and microsoft azure. In this blog, we will dive into the data ingestion part and tell you how to get the data in your platform by using aws cloud services.
Importance of Data Ingestion
These days, we can’t ignore the amount of data we produce and that can be collected by companies in any type of industry. A data platform helps you to get quick insights on that data without the need for lengthy processing steps.
But, before we can start using the data, we need to get it into our platform of course.

The diagram above shows the flow of data throughout a data platform. In the following blog stories, we will cover the other components such as storage, processing and data consumption (querying and visualization).
The data ingestion component is responsible for collecting data from different types of resources such as databases, ERP, CRM, (web) applications, data streams and so much more. The data will be stored in the storage layer of the data platform. Virtually any data source can be coupled to the data platform in one way or another.
Even though the amount of data sources you can ingest in your data platform is endless, you will find that in practice you only have about four main ways to ingest data from those sources: via File transfer, API calls, Database connection or Data Streams
Let’s investigate the services Amazon Web Services offers to ingest these four types of sources.
File-based sources
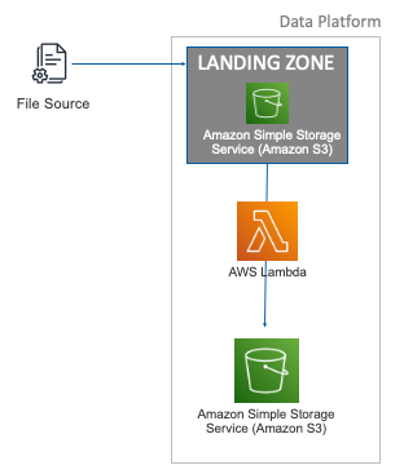
In AWS, files are stored in Amazon Simple Storage Service, better known as Amazon S3. This object storage system allows you to save objects or text files in buckets.
Within Amazon S3 you can set up a landing zone to which the data can be uploaded. When you drop files in this landing zone, they are transferred automatically into the raw layer of your Data Lake. (For more information on the different storage layers check out our previous blog on the general architecture of an AWS Data Platform. Or stay tuned for our next blog where we go into more detail on the subject).
The movement of data from the landing zone into the Data Lake is done by using AWS Lambda.
API-based sources
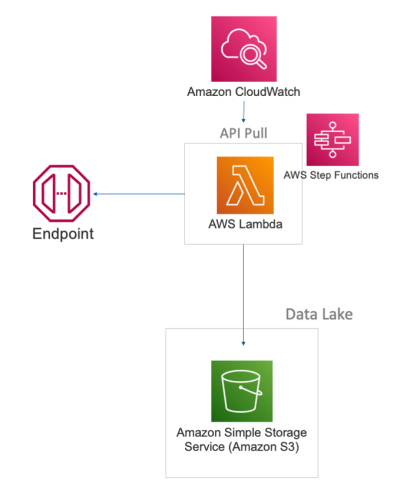
Lots of data integrations happen through APIs: programmatic interfaces on top of your source applications. An excellent tool to ingest data from APIs is AWS Lambda. Lambda is a serverless, event-driven compute service from Amazon. You can use this service to connect to the source API, transfer the data and store it in your Data Lake. The fact that is runs serverless means that you only pay for the actual running time of your job and nothing more.
You schedule this ingestion job by configuring a trigger in Amazon CloudWatch, which in its turn starts the Lambda function to ingest the API from the source endpoint.
AWS Lambda has some limitations, most importantly in the maximum execution time (15 minutes) and memory (10GB). You can overcome these by chaining multiple function executions trough AWS Step Functions.
Streaming-based sources
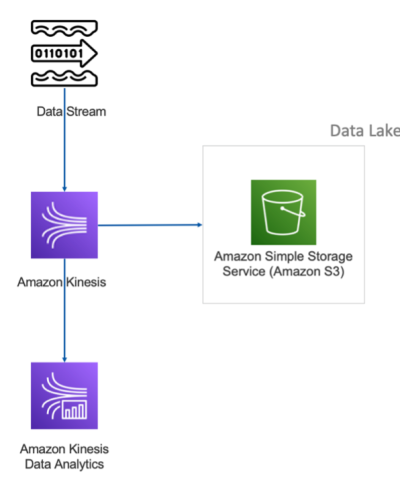
If you need to collect real-time streams of data into the platform, Amazon Kinesis Data Firehose can help you out. It is a fully managed service for delivering data directly into your Data Lake.
Amazon Kinesis can also be configured to transform streaming data before it’s even stored. You can also build streaming applications using AWS Glue. You can even analyze the data stream directly using Amazon Kinesis Data Analytics.
Database sources
Tons of information is stored in databases. There are many ways to import data from databases, but AWS does offer one very specific and interesting service for this use case: the AWS Database Migration Service (or DMS for short)
Using the DMS you can do one of two things: either a full sync of your source tables or all individual inserts, updates and deletions of data – also called Change Data Capture (CDC)
Both the full sync and CDC records can be sent directly to your Data Lake. You can also process your CDC records in real time using Amazon Kinesis – as seen in the chapter on streaming data sources.

Conclusion
Although you can ingest data from virtually any source, you generally can limit yourself to four different types of data ingestion: File-based, API-based, streaming data sources and databases.
- For File-based sources you can build a file landing zone in S3 which directly process the data as it comes in.
- APIs can be ingested using AWS Lambda.
- Streaming data is processed using Amazon Kinesis.
- And databases can be synced using the AWS Database Migration Service.
When this does look a bit overwhelming to you, or if you don’t want to spend a lot of time setting things up from scratch, do not despair! Take a closer look at the InfoFarm One Day Data Platform. A reference architecture in both AWS and Azure. We get you going with a fully operational data platform in only one day! More info on our website.
If you’re excited about our content, make sure to follow the InfoFarm company page on LinkedIn and stay informed about the next blog in this series. Interested in how a data platform would look like for your organization? Book a meeting with one of our data architects and we’ll tell you all about it!
