By Ben Vermeersch – Managing Partner
The data landscape is evolving at a rapid pace. New technology and terminology are emerging almost daily now. Everyone was happy with their data warehouse when suddenly data became big, and you needed a data lake to handle that data. Then people started talking about a data lakehouse. Or that you need a data platform. Or this hot new thing called a data mesh?!
As the data world is very eager to come up with new concepts it is very understandable that it’s hard to keep up. In this post I’ll try to explain all different concepts to you, so you can impress everyone with your thorough knowledge of the data landscape (although I must confess: this a topic I have failed to impress anyone with when at the bar).
Data Warehouse
Let’s start with the patriarch of data concepts: the Data Warehouse. The term has been around since the 1970’s and is very well known in every company that takes reporting seriously.
A Data Warehouse is a place where you store data in a structured way – usually in relational databases – for reporting or analytics. You build a data model in your warehouse to make it easy to query multiple data sources.
Within a data warehouse you usually have multiple logical layers of data: L1 (Staging), L2 (Data Store) and L3 (Reporting). The first layer has your data stored as-is. In L2 your data is transformed into a common database structure and L3 contains your views ready for reporting.
Typical for traditional data warehouses is that there is a need for schema-at-write: meaning you have to go through a processing step where you map data to a certain schema even when writing it to your staging area.

Data Lake
As the data generated in businesses exponentially grew throughout the years there developed a need to be able to store, structure and query that data easily without necessarily processing it beforehand or storing it in a database. Enter the Data Lake concept.
A Data Lake is file-based storage, meaning you can store any type of data there. Structured data like CSV, Excel or Parquet files. Unstructured data like PDF files and even binary data such as images, sound or video. So you can store any type of data, and later on decide what you want to do with it.
The big upside with modern data lakes is that you can query the (structured) data in your directly using SQL, without the need for a server running 24/7. This is on the one hand a big benefit in infrastructure cost. But on the other hand it also means you don’t need to let all of your data flow through an ETL-process and have to let it fit in a specific database schema before you can query it. This process is called schema-on-read and is specifically useful for exploratory data analysis.
The fact that you store your data as files and not in databases does not mean you can’t have tables, or data schemas in your data lake. You can use the same principles as a data warehouse, build L1, L2 and L3 data layers, facts and dimensions in the same way as you do with a normal data warehouse. The only thing that changes is that not everything needs to be a table or needs to adhere to one schema.
Data Lakehouse
While most of the things you can do with a Data Warehouse are also possible with a Data Lake, a Data Lake still has some specific disadvantages. The fact that everything is stored as a file and is processed as the data is read, comes at the cost of higher latency in your queries. Queries return in seconds, not milliseconds. And while for most reporting use cases this is more than fast enough, for some use cases where you require sub-second response times or where you query your data very frequently a regular Data Warehouse with database tables is more efficient.
This is why in modern data architecture, a Data Lake is often combined with a Data Warehouse. This architectural concept is called a Data Lakehouse.
In a Data Lakehouse principle, your Data Lake is the primary source of data. But when a specific use case requires it, parts of the data can be moved to a Data Warehouse for lower latency querying. This gives you the best of both worlds: a low-cost efficient store for all of your data and most querying needs, and a smaller high-cost option for specific use cases.
It doesn’t even have to matter for the consumer of the data where the data lives. As both a Data Lake and Warehouse have the concepts of tables, they can be easily used together. Modern Data Platforms even allow you to query and join data from both your Warehouse and Lake simultaneously.
Data Platform
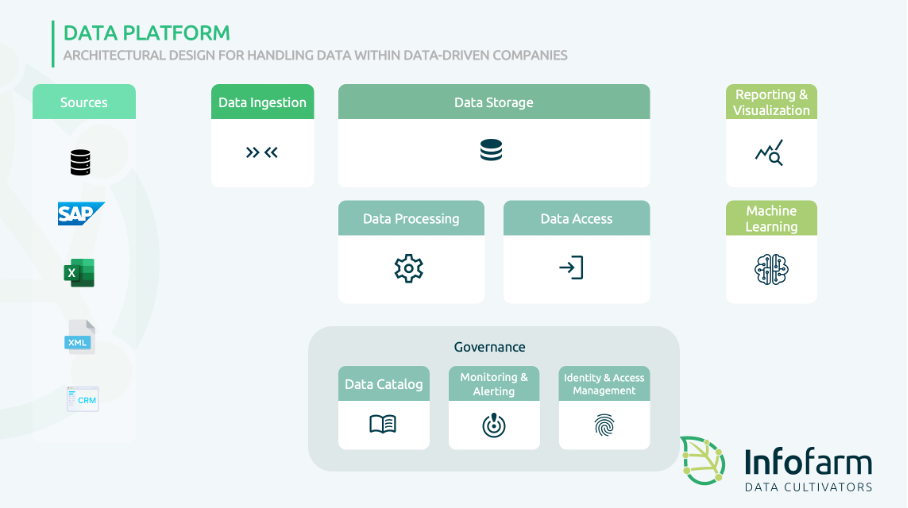
You’ve heard the name drop: a Data Platform. A Data Platform is not a mythical feature, or even a product or technology.
A Data Platform has all the tools you need to ingest, process, store, serve, visualize and analyze data. It provides governance services, monitoring, security and even machine learning services.
All components of a modern data platform deserve a chapter on its own. And what do you know: we’ve written a blog about it! Learn on how to set up a data platform in our blogs on building one in Amazon Web Services or Microsoft Azure.
Data Mesh
While a Data Platform is an architectural construct, a Data Mesh is an organizational one. Incorporating a Data Mesh structure in your organization means you decentralize the responsibility for making data and reports available throughout the organization.
Traditionally, all data and reporting responsibility is centralized within the IT department, or a BI department. When building a data mesh, you define a contract for the whole company on how data is made available, and how you broadcast to others what data you have available, but every department is responsible for serving and maintaining its own data. This can mean that every department gets their own data platform, even in different technologies. But using a single Data Platform where every department maintains its own data sources is also a valid way of working.
Incorporating a Data Mesh helps a lot in the data-awareness of every department in your organization. It does however also require a dedicated data team for every department, which might be a change in process for some. So this concept might not be for everyone.

To summarize
I hope this blog has helped you to shed some light on the myriad of different terms out there in the data landscape. To conclude, I’ll try to briefly summarize the main differentiators of every term mentioned in this post:
Data Warehouse: Setup of relational database servers to store data in a structured way for analysis and reporting. Schema at write means a processing step is required on all data.
Data Lake: File based storage for virtually any type of data: structured, unstructured or binary. Can be queried in the same way as a Data Warehouse. Schema-on-read means not all data has to be processed before going into the lake, at the cost of higher latency when querying.
Data Lakehouse: Combination of a Data Warehouse and a Data Lake. The Lake is used for the majority of use cases, while the Warehouse is used for specific cases where low-latency is a requirement.
Data Platform: Architectural construct of a combination of services to cover all data needs. A Data Platform has all the tools you need to ingest, process, store, serve, visualize and analyze data. It provides governance services, monitoring, security and even machine learning services.
Data Mesh: Organizational concept where you decentralize the responsibility for making data and reports available throughout the organization.
If you’re excited about our content, make sure to follow the InfoFarm company page on LinkedIn and stay informed about the next blog in this series. Interested in how a data platform would look like for your organization? Book a meeting with one of our data architects and we’ll tell you all about it!
